



新聞中心
時(shí)間:2018-09-25 13:53:46 次數:4640








一個(gè)故事
在很久很久以前,世界上生活著(zhe)許多(duō)種族,有人(rén)類,有矮人(rén),有精靈......他(tā)們有著(zhe)不同的(de)信仰,不同的(de)文化(huà),彼此相安無事。可(kě)是,有一個(gè)猥瑣男(nán)卻偏偏想要統治整個(gè)世界。
如何統治這(zhè)麽多(duō)不同文化(huà)信仰的(de)種族呢(ne)?猥瑣男(nán)想出一個(gè)馊主意,打造出幾枚擁有魔力的(de)戒指,免費送給不同種族的(de)領袖,讓他(tā)們可(kě)以更好地統治各自的(de)族人(rén)。

當各個(gè)種族的(de)領袖美(měi)滋滋地戴上各自的(de)魔戒,走上人(rén)生巅峰的(de)時(shí)候,猥瑣男(nán)又打造出一枚獨一無二的(de)至尊魔戒。他(tā)利用(yòng)至尊魔戒的(de)力量控制了(le)所有的(de)魔戒,從而控制了(le)各個(gè)種族的(de)領袖,繼而控制了(le)整個(gè)世界。

這(zhè)個(gè)故事告訴我們:數據庫和(hé)數據倉庫之間的(de)關系。
如果說,那個(gè)世界的(de)每一個(gè)生命個(gè)體都是一條數據記錄,那麽普通(tōng)的(de)魔戒的(de)地位就好比是數據庫,而至尊魔戒的(de)地位就好比是數據倉庫。


什(shén)麽是數據倉庫?
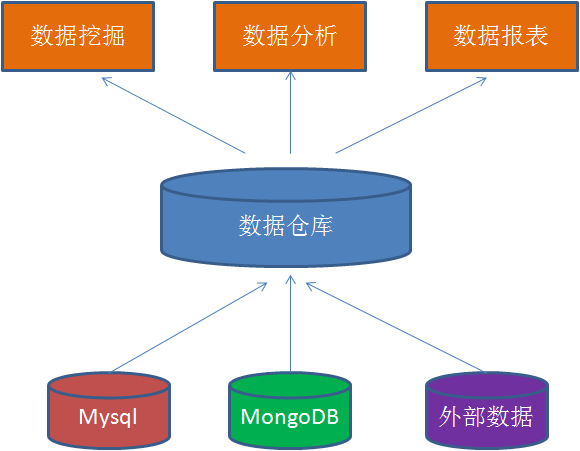
數據倉庫,英文名稱Data Warehouse,簡寫爲DW。數據倉庫顧名思義,是一個(gè)很大(dà)的(de)數據存儲集合,出于企業的(de)分(fēn)析性報告和(hé)決策支持目的(de)而創建,對(duì)多(duō)樣的(de)業務數據進行篩選與整合。它爲企業提供一定的(de)BI(商業智能)能力,指導業務流程改進、監視時(shí)間、成本、質量以及控制。
數據倉庫的(de)輸入方是各種各樣的(de)數據源,最終的(de)輸出用(yòng)于企業的(de)數據分(fēn)析、數據挖掘、數據報表等方向。
那麽,數據倉庫都有什(shén)麽特點呢(ne)?
1.主題性
不同于傳統數據庫對(duì)應于某一個(gè)或多(duō)個(gè)項目,數據倉庫根據使用(yòng)者實際需求,将不同數據源的(de)數據在一個(gè)較高(gāo)的(de)抽象層次上做(zuò)整合,所有數據都圍繞某一主題來(lái)組織。
這(zhè)裏的(de)主題怎麽來(lái)理(lǐ)解呢(ne)?比如對(duì)于滴滴出行,“司機行爲分(fēn)析”就是一個(gè)主題,對(duì)于鏈家網,“成交分(fēn)析”就是一個(gè)主題。
2.集成性
數據倉庫中存儲的(de)數據是來(lái)源于多(duō)個(gè)數據源的(de)集成,原始數據來(lái)自不同的(de)數據源,存儲方式各不相同。要整合成爲最終的(de)數據集合,需要從數據源經過一系列抽取、清洗、轉換的(de)過程。
3.穩定性
數據倉庫中保存的(de)數據是一系列曆史快(kuài)照(zhào),不允許被修改。用(yòng)戶隻能通(tōng)過分(fēn)析工具進行查詢和(hé)分(fēn)析。
4.時(shí)變性
數據倉庫會定期接收新的(de)集成數據,反應出最新的(de)數據變化(huà)。這(zhè)和(hé)特點并不矛盾。


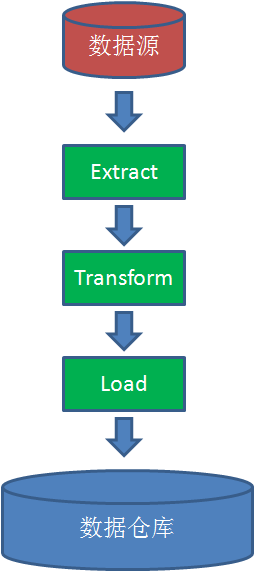
什(shén)麽是ETL?
ETL的(de)英文全稱是 Extract-Transform-Load 的(de)縮寫,用(yòng)來(lái)描述将數據從來(lái)源遷移到目标的(de)幾個(gè)過程:
1.Extract,數據抽取,也(yě)就是把數據從數據源讀出來(lái)。
2.Transform,數據轉換,把原始數據轉換成期望的(de)格式和(hé)維度。如果用(yòng)在數據倉庫的(de)場(chǎng)景下(xià),Transform也(yě)包含數據清洗,清洗掉噪音(yīn)數據。
3.Load 數據加載,把處理(lǐ)後的(de)數據加載到目标處,比如數據倉庫。
主流的(de)數據倉庫有哪些?


這(zhè)個(gè)Hive又是何方神聖呢(ne)?

确切地說,Hive是基于Hadoop的(de)數據倉庫工具,可(kě)以對(duì)存儲在HDFS上的(de)文件數據集進行查詢和(hé)分(fēn)析處理(lǐ)。Hive對(duì)外提供了(le)類似于SQL語言的(de)查詢語言 HiveQL,在做(zuò)查詢時(shí)将HQL語句轉換成MapReduce任務,在Hadoop層進行執行。
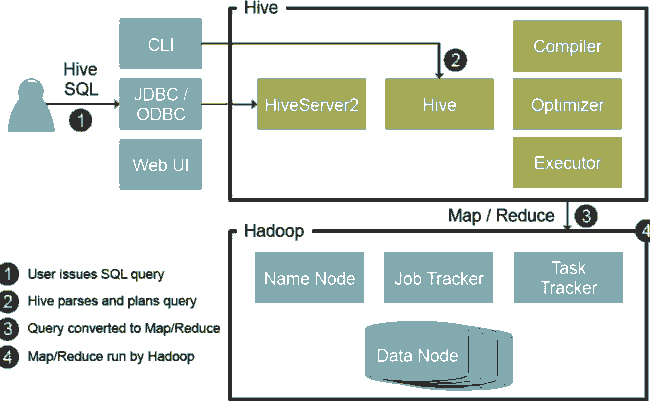
這(zhè)裏有幾個(gè)名詞需要解釋:
1.HDFS
Hadoop的(de)分(fēn)布式文件系統,在這(zhè)裏作爲數據倉庫的(de)存儲層。圖中的(de)Data Node就是HDFS的(de)衆多(duō)工作節點。
2.MapReduce
一種針對(duì)海量數據的(de)并行計算(suàn)模型,可(kě)以簡單理(lǐ)解爲對(duì)多(duō)個(gè)數據分(fēn)片的(de)數據轉換和(hé)合并。
關于HDFS和(hé)MapReduce的(de)具體知識,這(zhè)一期暫時(shí)不做(zuò)展開,小灰會在後續的(de)漫畫(huà)中詳細介紹。





幾點補充:
1.對(duì)于大(dà)數據方向,小灰也(yě)僅僅了(le)解皮毛,漫畫(huà)中若存在錯誤或是描述不全面的(de)地方,還(hái)請大(dà)家多(duō)多(duō)指正補充。
2.關于Teradata,小灰曾經有幸在這(zhè)裏工作過,雖然不是從事數據倉庫領域。Teradata 的(de)确是一款很強大(dà)的(de)商業數據倉庫,對(duì)此有興趣的(de)同學,可(kě)以百度學習(xí)一下(xià)具體知識。



巨龍信息公衆号







