



新聞中心
時(shí)間:2022-03-28 17:06:12 次數:2930
産品介紹

智立方是巨龍信息研發的(de)一款跨數據平台的(de)數據挖掘、分(fēn)析、建模工具。面向各行各業在大(dà)數據建設過程的(de)應用(yòng)訴求,緻力于構建智能數據體系,打造更便捷、更易用(yòng)的(de)大(dà)數據生産力平台,提供從數據準備、數據建模、分(fēn)析探索、數據可(kě)視化(huà)到數據API服務等全鏈路的(de)完整解決方案,充分(fēn)滿足建設數據過程中的(de)多(duō)樣複雜(zá)需求,幫助客戶打通(tōng)挖掘數據價值,促進在業務場(chǎng)景中應用(yòng)大(dà)數據。
産品特征
全流程體驗:提供“一站式”體驗,從數據接入、數據準備、數據建模、分(fēn)析探索、數據可(kě)視化(huà)到數據API服務,覆蓋全流程形成完整閉環。
可(kě)視化(huà)建模:提供全程可(kě)視化(huà)的(de)模型搭建,通(tōng)過拖拽的(de)交互方式,采用(yòng)引導式及“搭積木(mù)”般的(de)畫(huà)圖式界面幫助用(yòng)戶實現數據、組件的(de)靈活的(de)組合,從而快(kuài)速地獲得(de)高(gāo)質量的(de)模型搭建。
數據可(kě)視化(huà):提供常見的(de)可(kě)視化(huà)圖表和(hé)探索分(fēn)析能力,讓用(yòng)戶可(kě)以便捷的(de)将模型結果采用(yòng)圖表的(de)形式展現,讓數據更生動更直觀。
簡捷高(gāo)效易用(yòng):純拖拽式操作,能夠極大(dà)地降低建模的(de)技術門檻,讓複雜(zá)、繁瑣的(de)數據建模過程變更簡單、高(gāo)效。
數據應用(yòng)簡單:模型結果可(kě)便捷的(de)生成儀表盤,以及快(kuài)速生成數據API的(de)能力,以滿足不同的(de)業務應用(yòng)場(chǎng)景對(duì)模型結果的(de)使用(yòng)需求,非常方便實現建模成果的(de)分(fēn)享和(hé)使用(yòng)。
技術淺析
标準化(huà)數據集
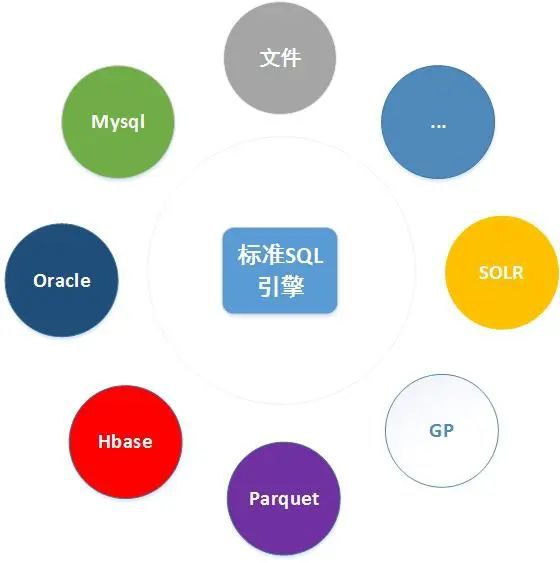
■統一數據集模型:适配主流關系庫,NOSQL庫,文件,統一數據訪問方式,方便項目的(de)快(kuài)速擴展,打通(tōng)各個(gè)異構庫之間的(de)數據集計算(suàn)過程
■标準化(huà)SQL解析引擎:實現異構庫之間跨庫JOIN,分(fēn)組統計等查詢檢索業務
統一的(de)表達式框架
■可(kě)擴展的(de)表達式定制框架:方便根據項目定義特定的(de)分(fēn)析計算(suàn)公式,滿足多(duō)變複雜(zá)的(de)項目定制需求
■統一的(de)表達式解析器:滿足表達式邏輯的(de)統一複用(yòng),實現一次編寫,随處可(kě)用(yòng)
圖形化(huà)模型構建
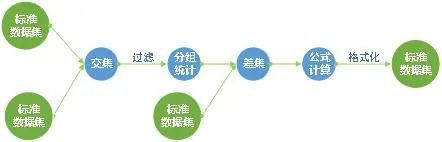
■标準化(huà)數據集:用(yòng)戶無需關注使用(yòng)的(de)庫類型或數據類型,統一标準化(huà)爲二維數據集
■過程可(kě)視化(huà):通(tōng)過“拖”,“拉”,“拽”的(de)方式配置模型計算(suàn)的(de)流程,步驟與步驟之間松耦合,每個(gè)步驟輸出新的(de)标準數據集,方便用(yòng)戶控制數據的(de)計算(suàn)和(hé)流轉
■計算(suàn)過程插件化(huà):插件化(huà)的(de)計算(suàn)過程,可(kě)快(kuài)速響應項目定制的(de)過程插件
■内置主流數據集計算(suàn)插件:提供主流的(de)集合運算(suàn)插件,适應各種數據集負責運算(suàn)
■快(kuài)速即席查詢配置:計算(suàn)出的(de)結果集可(kě)快(kuài)速通(tōng)過即席查詢配置構建方案,發布到前台,給用(yòng)戶提供快(kuài)速的(de)結果集檢索
靈活高(gāo)效的(de)标簽體系
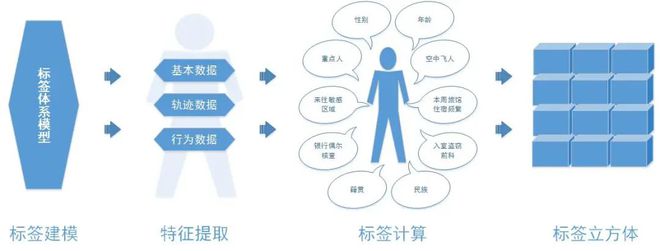
■自定義标簽體系:自定義标簽項,标簽值,标簽分(fēn)類;支持枚舉标簽,複雜(zá)業務标簽,基本類型标簽的(de)定義;方便用(yòng)戶快(kuài)速構建行業标簽體系。
■複雜(zá)标簽計算(suàn)邏輯:支持複雜(zá)标簽計算(suàn)邏輯的(de)表達式編寫,支持事件觸發的(de)标簽計算(suàn)。靈活應對(duì)各種複雜(zá)業務場(chǎng)景。
■高(gāo)效的(de)标簽立方體:分(fēn)布式标簽立方體,可(kě)擴展的(de)存儲架構,支持超過10000+的(de)标簽項的(de)毫秒級檢索,研判,比對(duì)。爲行業用(yòng)戶的(de)行爲決策分(fēn)析提供強大(dà)支撐。
高(gāo)性能關系分(fēn)析模型
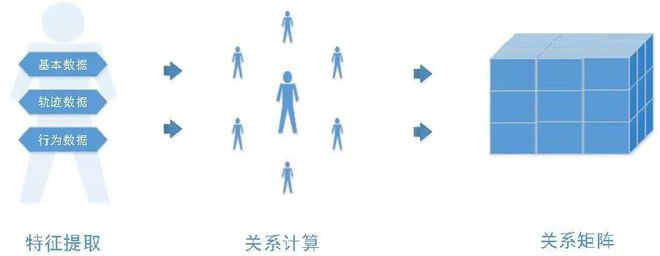
■高(gāo)性能關系檢索:快(kuài)速定位帶時(shí)間周期的(de)行爲關系人(rén),根據關系親密度排分(fēn),不落下(xià)任何可(kě)疑人(rén)員(yuán)。
■複雜(zá)關系計算(suàn)邏輯:支持複雜(zá)關系計算(suàn)邏輯的(de)表達式編寫,靈活應對(duì)各種複雜(zá)業務場(chǎng)景,如同車廂,相鄰位置等。
數據集的(de)快(kuài)速比對(duì)
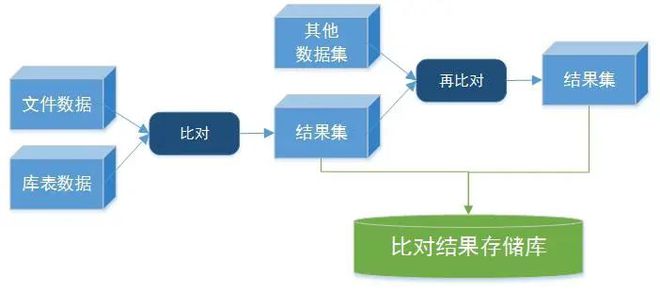
■比對(duì)數據集的(de)快(kuài)速構建:支持文件,數據庫表,SQL語句等多(duō)種數據集的(de)構建,适應各種複雜(zá)場(chǎng)景。
■高(gāo)效的(de)比對(duì)引擎:分(fēn)布式比對(duì)引擎,實現千萬,億數據級數據的(de)秒級比對(duì),10億級數據的(de)分(fēn)鐘(zhōng)比對(duì)。
■結果集的(de)自定義存儲與再次比對(duì):可(kě)将結果集根據用(yòng)戶要求存儲或再次生成比對(duì)方案,方便用(yòng)戶快(kuài)速洞察數據集與結果集之間的(de)關注信息。
■比對(duì)隊列的(de)合理(lǐ)調度:根據集群情況合理(lǐ)安排比對(duì)任務,保證比對(duì)引擎的(de)高(gāo)可(kě)用(yòng)。
高(gāo)性能任務執行
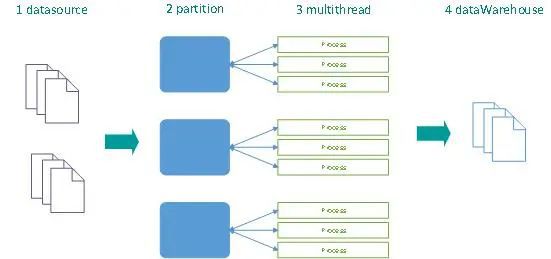
■任務的(de)水(shuǐ)平切分(fēn)
任務根據分(fēn)區(qū)自動被分(fēn)片到多(duō)台DMC-分(fēn)析引擎中,每個(gè)分(fēn)析引擎的(de)執行容器使用(yòng)多(duō)線程并發的(de)對(duì)數據進行加工處理(lǐ)後加載到數據倉庫中。當源頭庫單表數據量巨大(dà)時(shí),可(kě)極大(dà)提升整體的(de)數據集成效率和(hé)性能
高(gāo)擴展任務調度
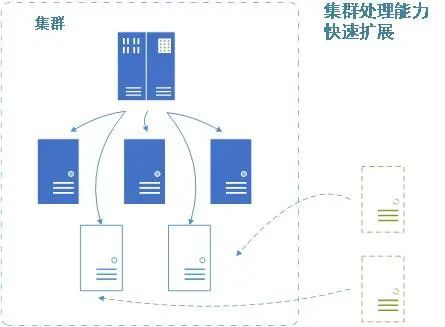
■集群處理(lǐ)能力的(de)線性擴展
Ø 集群處理(lǐ)能力的(de)快(kuài)速擴充
Ø 集群自動識别和(hé)熱(rè)部署新增分(fēn)析引擎
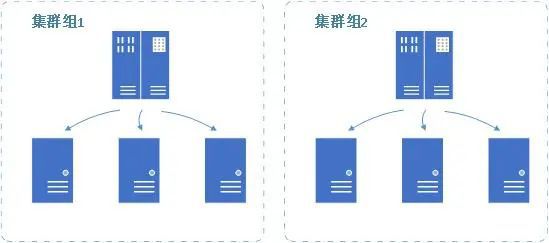
■多(duō)集群組
Ø 根據業務劃分(fēn)集群組,使關注點分(fēn)離
Ø 集群組有利于異常幹擾的(de)隔離
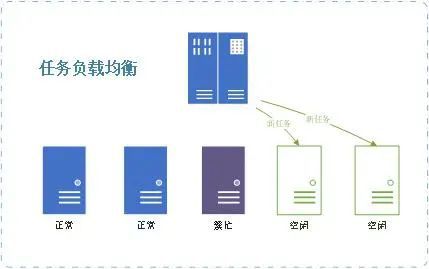
■任務的(de)分(fēn)布式調度
Ø 帶權重的(de)負載均衡算(suàn)法,可(kě)根據設備處理(lǐ)能力安排并發任務數
Ø 任務調度中心對(duì)集群環境的(de)自動負載均衡



巨龍信息公衆号







